世界最速のお魚と言えばカジキ類で,泳ぐ速度は時速100km/hを超えるとか.55ノット程になるのでこれはMk-48魚雷にも匹敵するほどです.
一方ちょっとチートな高速お魚としては,お馴染みトビウオが飛行中に最大70km/hほどに達するとか.
今日はそんな若干チートな高速化のお話(?)ということで,SSE組み込み命令について.
SSEやAVXといえばお馴染みSIMD命令で,それをプログラムから構造体と関数の形式で高移殖に記述する方法がSIMD組み込み関数(SIMD Intrinsic)なわけですが,これを使ってごく典型的なベクトルの内積計算を高速化してみました.
ベクトルの内積の高速化と言えば星の数ほどもされてる話なわけで,いまさら魚の情報なんか役に立つ気は全くしないのですが,純粋に自分でやらないとわかんない>< ということで,
- とにかく書いてみよう
- 効果の程はいかに?
を調べてみたくて,やってみました.
もちろん完全に最適化されたコードでもなく,この記事の内容は無保証です.
参考は主に
SSE.浮動小数点演算手動最適化は本当に効果的なのか – デー
インテル(R) Advanced Vector Extensions (インテル(R) AVX) の組み込み関数
です.
テストコード
いきなりです.ハイ.
比較手法
なんか論文みたいになっとる(゜∀。)アヒャ
- 普通に書いた場合
- SSEで書いた場合
- AVXで書いた場合
-
AVXで書いた場合をさらに高効率化した場合
- AVX命令は1度に数クロック要するのでスーパースカラに放り込めるよう中途半端なループアンロールをしたコード
- これでスループットの向上が見込める
- 何言ってるかわからないと思うのでコードを見てw
- SSEでも同様と思うけどやってない
- (今回は対応プロセッサが未出荷なので省く)さらにFMA命令を用いて最適化した場合
テストプログラムの概要
このプログラムは,
- 次元を変えながら
-
各次元数ごとに各手法での平均計算時間を出力する
- 平均計算時間は,250ミリ秒間に渡りひたすら繰り返し実行し求める
というものです.
これを,グラフを出力するためにgnuplotで読める形式にしています.
dim time1 time2 time3 time4 dim time1 time2 time3 time4 dim time1 time2 time3 time4 ...
左端の値は次元数,各値は内積計算1回当たりの平均時間(ミリ秒)です.
ソース
実行方法と出力内容
プログラムは次の要件を想定しています.
-
Linux
-
Windowsの場合は若干ソースを修正する必要あり
- ソース中の,アラインメントのattribute記述をdeclspec記述にするなど.詳細はぐg(ry
- コンパイルオプションも変更の必要あり?基本的にVC++で実行はできると思います
-
Windowsの場合は若干ソースを修正する必要あり
-
GCCの新しい方がいい
- C++11有効に
- Boost
もちろんCPUがSSEやAVXに対応している必要があります.
SSEはいいでしょうけどAVXがない場合(CPUがSandyBridge以前)は,該当する関数呼び出しとimmintrin.hのインクルードを消せばおkです.
ただしすみません,時間計測には非公開のおさかなライブラリを使っています.この部分は適切に置き換えてください.
あとはコンパイルして実行するのみ.-mavxオプションが必要です.
% g++ -std=c++0x -Wall simd.cpp -O3 -mavx % ./a.out 8 0.000023 0.000027 0.000028 0.000026 16 0.000025 0.000028 0.000028 0.000032 32 0.000027 0.000030 0.000029 0.000044 ...
細かいけど重要な小話〜アラインメント〜
- SSEやAVXでレジスタに効率的に読み込む(_mm_load_ps命令など)には,メモリを16バイト(SSE)や32バイト(AVX)境界にアラインメントする必要がある
- nバイト境界にアラインメントするとは,領域の先頭アドレスをnで割った余りが0になること
- ローカル配列変数ならattribute指定によりアラインメントされて領域確保される
- 動的確保でattribute指定しても,なんかされない(上のコードでは残ってますがw)
-
なので強引な解決方法
- ちょっと大きめに確保しといて,32バイト境界アラインメントの条件を満たすまで確保された先頭ポインタをインクリメントしてます(・∀・)
- 領域はかならず4とか8バイト境界にアラインメントされてるため,必ずいつか32バイト境界に達します
- このあたりが131行目から138行目
- アラインメントされない領域での読み書きは,_mm_loadu_psなどの命令を使います
動かした結果
手元の環境は,Core i7 3770k (3.5GHz)です.目下最新かつシングルスレッドに関しては最速なプロセッサですね.
ちなみにコアごとに持っているL2キャッシュは256KB,float配列にして65536要素にあたり,今回のプログラムでは次元が32768のときに該当します(2ベクトルの内積なので).
結果グラフ
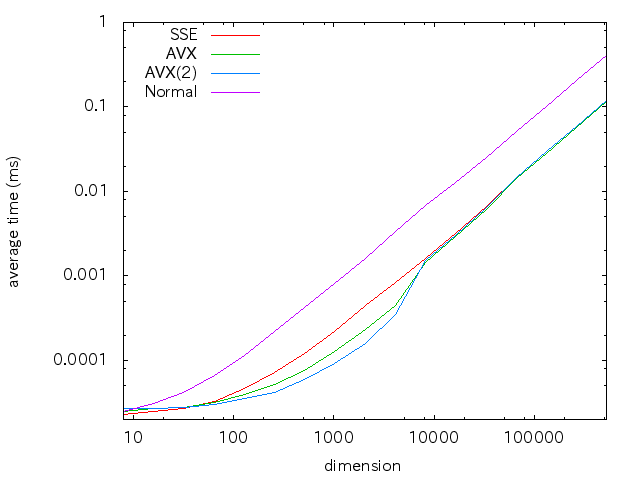
まず,次元数と計算時間の関係グラフ.
上述のプログラムの出力そのままグラフにしたものです.
続いて,非SIMDコードに対する倍率のグラフ.
プログラムをちょっと書き換えるとこの出力になります.
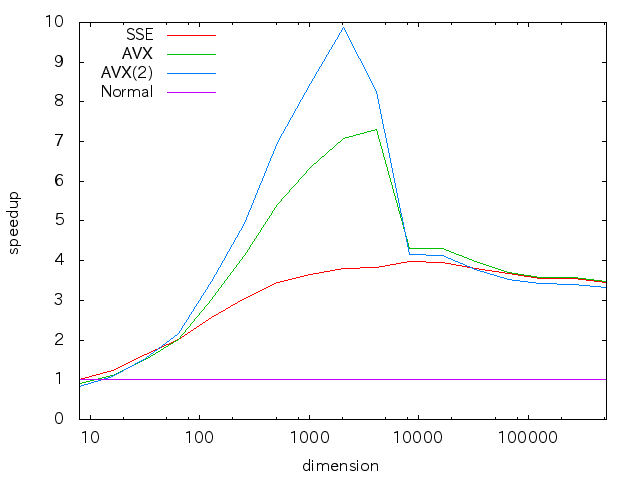
なおどちらのグラフも次元を(2^24程度まで)増やしても,そのままの関係が続きました.
考察
両方のグラフを眺めてみて・・・.
-
最大で10倍のスループットというのは驚き
- AVXではfloatの演算は8並列になるわけだけど,
- アラインメント周りの調整とかスーパースカラ機構になるべく乗りやすくした当たりでそれ以上に効いたか?
-
だいたい8192次元,つまりデータ量にして8192*sizeof(float)*2=64KBに達すると,速度差がなくなってますね
- このプロセッサは各コア32KBのL1データキャッシュを持ち,そこまではキャッシュにまるごと乗るからでしょう
- それを超えると,命令実行に対して転送時間の方が効いてきて速度差がほとんど出ない状態になるぽい
- L2キャッシュの影響がここではそれほど出ていないことが意外
今回は演算回数とデータ量が同じ場合だったのでこのような結果になったようです.
データ量が少なくてかつ,演算量とデータ量の関係が高次(二乗とか)の場合にはかなり効いてくると思われます.
それこそ,画像の線形フィルタリングとかですね.
まとめ
SIMDの組み込み関数を使って,SSEやAVXのごく限られた1側面ですが性能向上を見てみました.
プログラムの実装自体は簡単でしたが,同時に,SIMD化すれば綺麗に速くなってくれるわけじゃないという当然のことを改めて示しました.
この若干のコストとリスクの上でも必要であるかどうかちゃんと検討してから採用しないといけませんね.
素晴らしい記事をありがとうござます。参考になりました。
>Windowsの場合は若干ソースを修正する必要あり
ということで、この記事のソースを参考にVisual C++ 2012/2013版を作成してみました。参考になれば幸いです。
連続投稿失礼します。
記事のsimd.cppのVisual C++ 2012/2013版は下記リンクです。
https://gist.github.com/MtShan/375a371f0f215db85540
ご参考になったようで幸いです!&VC++版の公開ありがとうございます!
そういえば今はFMAの使えるAVX2搭載CPUが出てるので(Haswell)、こちらも試してみたいですね。