2022シーズンのJリーグの全日程も無事発表されました。
今季は開幕戦の発表が非常に早かったので例年であれば遠征計画を立てるのにとても助かったところですが、いかんせんコロナ禍とあって遠征計画の立てようがないのがモヤモヤするところです。
今季は開幕戦の発表が非常に早かったので例年であれば遠征計画を立てるのにとても助かったところですが、いかんせんコロナ禍とあって遠征計画の立てようがないのがモヤモヤするところです。
http://2022シーズンの日程が発表【Jリーグ】:Jリーグ.jp
観戦に行ける試合を検討するために電子データ形式でiPhoneやGoogleカレンダーに推しチームの全日程が今すぐ入ってほしい皆さんのために、おそらく日本最速(?)でicalカレンダー形式のデータを作成しました。
jleague2022-ical – Google Drive
これらのicsファイルは再頒布不可とします。Google Calendar等に取り込んだ上で共有カレンダーとすることは不可です。個人のカレンダーのみでご利用ください。
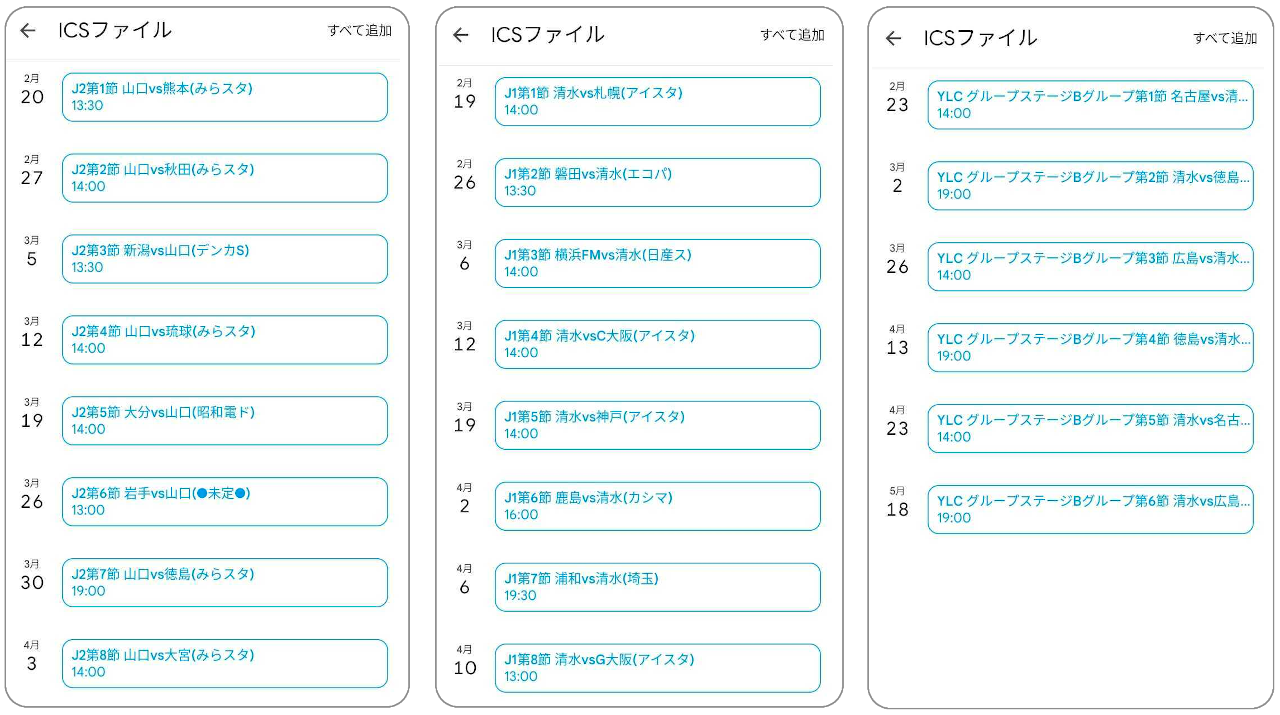
Jリーグデータサイトの日程表を手作業でCSV化し、こちらの自作script(その後Github化)でical形式に変換したものです。コードについてはMITライセンスとします。
活用方法としては、PCやスマートフォンであればicalファイルをダウンロードしてそのまま開くと標準のカレンダーアプリに取り込むことができます。またicalファイルをダウンロードしGoogle Calendarに取り込むことも可能です。
内容の正誤および今後の日程の確定に伴うアップデートについては一切無保証です。
今はとにかくコロナ禍が早く収束し観戦に足を伸ばせるようになることを願い、JリーグファンとしてはJリーグと世間様の足を引っ張るような行動をしないよう気をつけたいものです。
なお、Jリーグのマスコットはレノ丸が最強です。
変換スクリプトで地味にハマったところメモ
- ブラウザからcsvにコピペするとSJISになってしまうこと
- ical形式のタイムゾーン指定。とくに、RFC2445を参考にしてZをつけてしまうとGMT扱いとなりカレンダー上で9時間ずれる