さて、あるサーバ1台が数百GBにもなる巨大なファイル(群)を持っているとします。
このファイル群を、そのサーバに接続された他の複数(大量)のサーバのローカルディスクにコピーしたいです。
以後これを便宜的にbcast cpと呼ぶことにします。
rsyncを1台ずつ回すのが頭悪い方法なのは明らか。当然NFSなどを立てて共有するというのも本質的にはそれと同じ。
同僚のiwiwiさんがちょうど集団通信アルゴリズムの話をしていたのを聞いて、それを活用して効率的にファイルをバラまくようなアドホックなスクリプトを書いて、ときどき使えそうなのでまとめておきました。
「やってみた」ぐらいの話なのでガチ勢の方たちにはƱ”-ʓ飲んで寝ていてほしいです。
アルゴリズム
binomial tree broadcastというアルゴリズムなのだそうです。MPIにも実装されているそうです。
データをすでに持っていて送信側にいるホストをマスター、まだ持っておらず受信側にいるホストをスレーブと便宜的に呼びます。
あとはこんな雰囲気でコピーしてくだけ。名前を知らなくても普通に思いつくしなんも難しいことないですね。
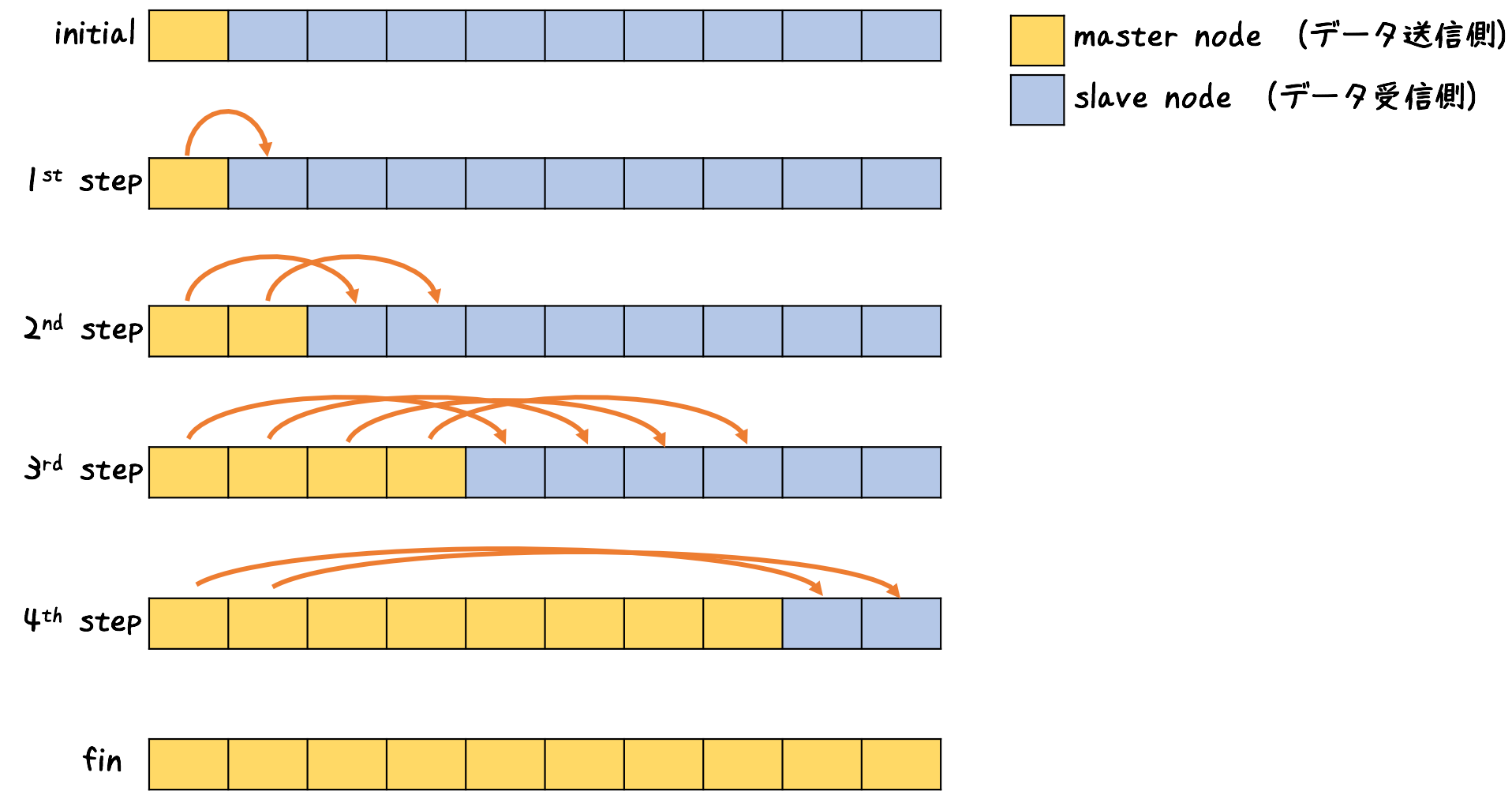
理想的な通信モデルのもとではn台に対してO(log(n))の時間オーダーでデータを送ることができます。
これを単に、shellで行えるようにしただけという正直あまり新しい価値のない仕事が、この記事の業績です。
前提
-
任意のサーバの間のコピーは失敗なく行われるとします
- ネットワークの接続性
- 互いにSSHできること
- 互いにrsyncできること
- 任意のサーバの間の帯域は全て同じとみなします
-
コピーされるファイル群のパスは全てのサーバで同一になるものとします
- どのサーバでも/home/xxx/foobar/というディレクトリがコピーされている形です
コード
# bcast_cp.py
def gen_copy_command(masters, slaves, parent_path, target_dir):
if len(masters) == 0:
masters.add(slaves.pop())
for master, slave in list(zip(masters, slaves)):
print('ssh {0} "rsync -a --delete {2}/{3} {1}:{2}/" &'.format(master, slave, parent_path, target_dir))
slaves.remove(slave)
masters.add(slave)
print('wait')
parent_path = '/home/xxx/'
target_dir = 'foobar' # Mustn't have '/' in its tail
masters = {'host0'}
slaves = {'host{}'.format(i) for i in range(1, 128)} # 名前解決可能なホスト名の集合
gen = 0
while len(slaves) is not 0:
print('echo step {}'.format(gen))
gen_copy_command(masters, slaves, parent_path, target_dir)
gen += 1
このようなコードによって、bcast cpを実際に行うシェルスクリプトを生成します。
コピー元ホスト、コピー先ホスト達はハードコードされていますが、argparseなどを使って引数で与えられるようにするともうちょっとイカした作りになると思います。
実行方法
あとはこのシェルスクリプトを実行するのみです。
したがって、bcast cpを行うのはこんなかんじのコマンドになります。
% python bcast_cp.py | sh
コードのデザイン
アルゴリズムはかんたんに解説したとおりです。
実装上のデザインを一応かんたんに解説。
あるホストAからあるホストBにファイルをコピーするために、
SSHでホストAに入り、「ローカルディスクからホストBへのrsync」を実行させます。
これによって、bcast cpを管理しているホスト(このスクリプトを実行しているホスト)の帯域は全く食いつぶさず、ダイレクトにホストAおよびBの間でやり取りをしてくれます。
で、1つの世代のコピーでは複数のマスター・スレーブペアでのコピーを同時並列で走らせるために、これらのコマンドは&をつけてバックグラウンド実行させます。
waitコマンドを使うとバックグラウンド実行したコマンドが全て終了するまで待ってくれるので、これにより1世代の同期をとることができます。
(このへんの同時並列実行&同期をシンプルに行いたいため、pythonでshellコードを吐いてshに食わす仕組みにしました。マルチスレッド化などすればフルpython化することが可能です。)
rsyncを使っているのは単にもとのファイル群に変更があったときにもっかいbcast cpをするのを速くするためで、1発限りであればscpでもOKです。
SSHでマスターに入りスレーブへのコピーをさせる作りであるため、このスクリプト自体は各ホストにアクセス可能なホストであればどこで走らせてもOKです。
各ホストにおいて、SSH設定に”StrictHostKeyChecking no”をつけておくことを推奨します。
マスターからスレーブへのコピーが失敗した場合(ディスク不足などなど)のエラーハンドリングはしていませんが、sshコマンドの戻り値をチェックして0以外であれば停止するようにするなどすれば対処可能です。
※ただし、pythonでshell用コードを吐くというstaticな構成のため、「失敗した場合そのホストを除いて続行する」という手が使えません。これは今後の課題です。
性能
実験をしてみました。
10GBEで接続された41台のサーバーで、そのうちの1台が、下記のようにして生成された1GiBのファイルを持っています。
% mkdir hoge; cd hoge % dd if=/dev/urandom of=random_1GiB.dat count=1024 bs=1048576
L2/L3スイッチのスペックは不明です。
各サーバはヒマしているわけではなく、(NFSからのデータ読み込みを含む)計算処理をしています。
単純に数十台のサーバの計算を全部止める政治力もなければ、この実験にそれほどの価値もないからです。
これらの点で、この実験は厳密な評価では全くありません。参考程度に。
40台へのbcast cpですので、理論的には1台へのコピーの6倍の時間程度で完了することになります。
1台へのコピーは、53秒でした。1台ずつ単純にループしていると、x40でおよそ35分と少々かかることになります。
上記のスクリプトを利用したbcast cpでは、5分6秒で終了することになりました。単純ループの7倍ほどと、ほぼ理論値どおり(理論値よりやや速い)結果になりました。
この方法のスケーラビリティを阻害しうる最大の要因はネットワーク全体としてのキャパ(主にL2/L3スイッチの能力)だろうと予想していますが、今回の実験条件では問題とはならなかったようです。台数の問題でもあり、またどんなバックボーンネットワークを持っているかにもよると思います。
まとめ
ここで使ったのは初歩中の初歩中の初歩ですけど、集団通信アルゴリズム、おもしろそう!